← Back to all projects
Energy-Aware Learning for Optimized Drone Fleet Coordination in Urban Delivery
Developed a data-driven energy prediction pipeline for quadrotor flight using real-world
telemetry data from the HiPeR Lab at UC Berkeley. The goal was to enable energy-aware
fleet coordination for urban drone delivery by accurately predicting energy consumption
under varied flight conditions.
Python
PyTorch
Transformers
LSTM
Bi-LSTM
RNN
Sim-to-Real
Key Results
95%
Prediction accuracy (R²)
4
Architectures benchmarked
Sim→Real
Validation framework built

Fig 1. End-to-end system architecture; from flight simulation through observation construction to energy prediction
Problem & Motivation
Urban drone delivery requires precise energy management - a drone that runs out of
battery mid-flight is not just an inconvenience, it's a safety hazard. Existing
energy models rely on simplified physics that don't capture the nonlinear dynamics
of real quadrotor flight (wind disturbances, payload variation, battery degradation).
This project asked: can we learn energy consumption models directly from flight data
that are accurate enough to enable fleet-level coordination and routing decisions?
Approach
Using real-world telemetry data collected from the HiPeR Lab's quadrotor testbed,
I built and compared four deep learning architectures for energy prediction:
- Vanilla RNN — baseline sequential model
- LSTM — captures long-term dependencies in flight trajectories
- Bi-LSTM — bidirectional context for improved temporal modeling
- Transformer — attention-based architecture for global sequence understanding

Fig 2. Domain randomization strategy and model training pipeline with architecture benchmarking
Each model was trained on flight telemetry features (velocity, acceleration,
orientation, motor commands) to predict cumulative energy consumption. I designed
a consistent evaluation framework to compare convergence, accuracy, and
generalization across flight conditions.
Results
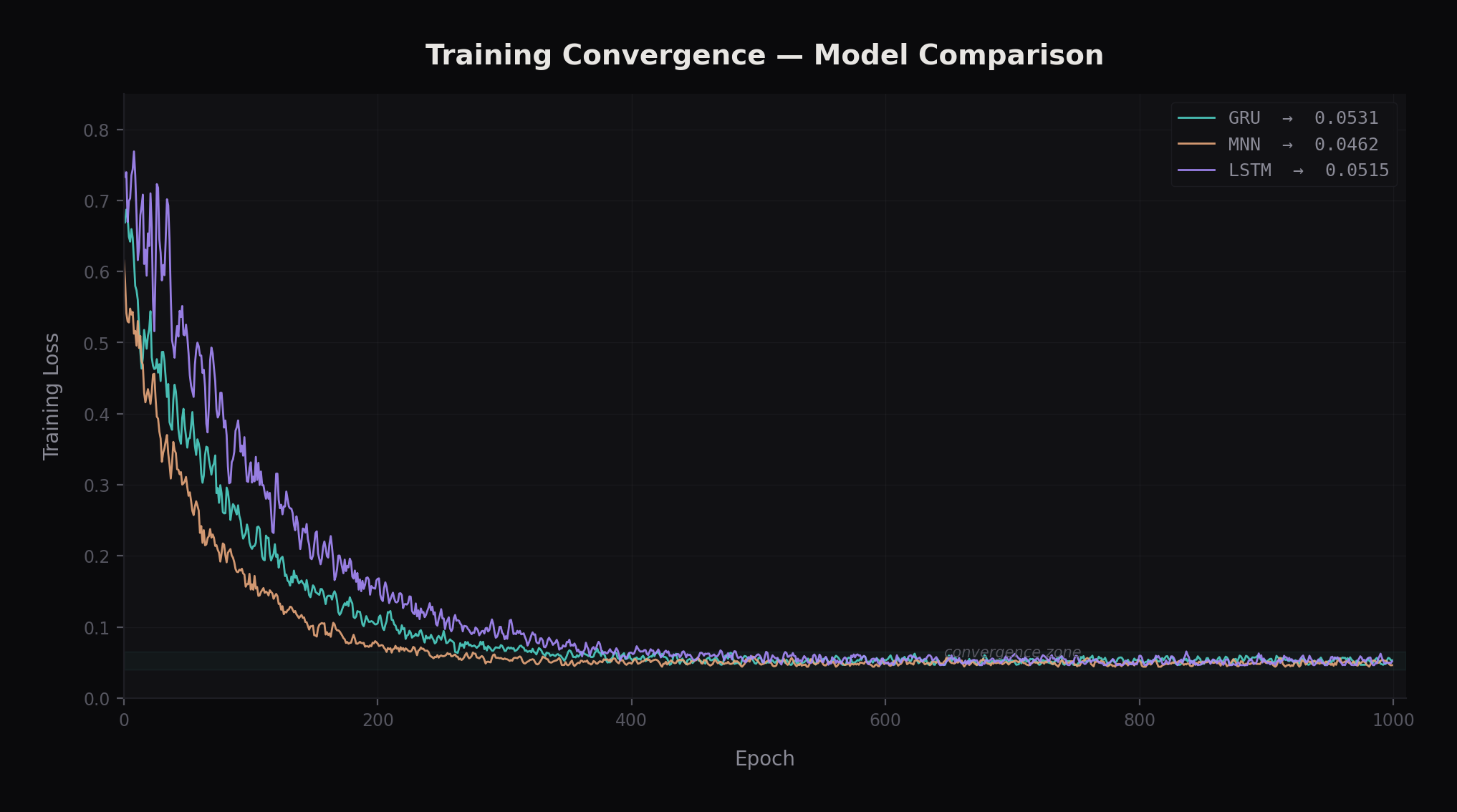
Fig 3. Training convergence - GRU, MNN, and LSTM all converge to ~0.05 loss
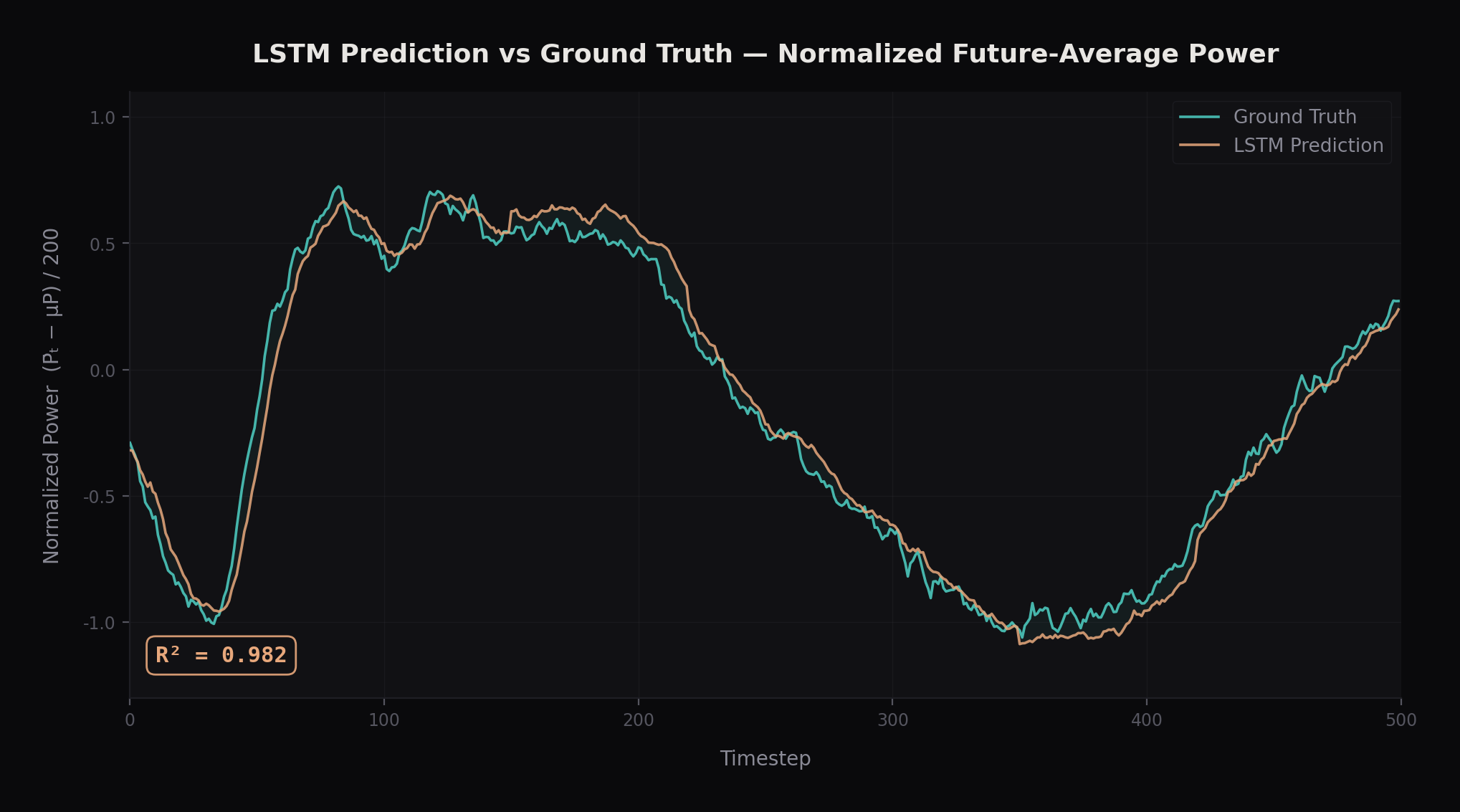
Fig 4. LSTM prediction vs ground truth - R² = 0.95
The best-performing model achieved 95% prediction accuracy (R²), demonstrating
that data-driven approaches can reliably model the complex energy dynamics of
quadrotor flight. The prediction is temporally smooth and tracks major power trends. p95 forward latency < 0.2 ms/step, well under the 20 ms (50 Hz) control budget.
Sim-to-Real Validation
A key contribution was the development of a sim-to-real validation framework.
Models trained on simulation data were evaluated against real-world flight
telemetry to assess deployment feasibility and identify the domain gap.
[ To be updated soon: sim-to-real comparison plot (ongoing)]
Fig 5. Sim-to-real transfer analysis
What I Learned
This project deepened my understanding of sequence modeling for physical systems,
the challenges of sim-to-real transfer, and the practical considerations of
deploying ML models for safety-critical robotics applications. Working with
real flight data, with all its noise and edge cases, was fundamentally
different from clean simulation datasets.